2026
Multi-agent Collaboration with State Management
Mengyang Liu, Taozhi Chen, Zhenhua Xu, Xue Jiang, Yihong Dong
Under review. May 2026
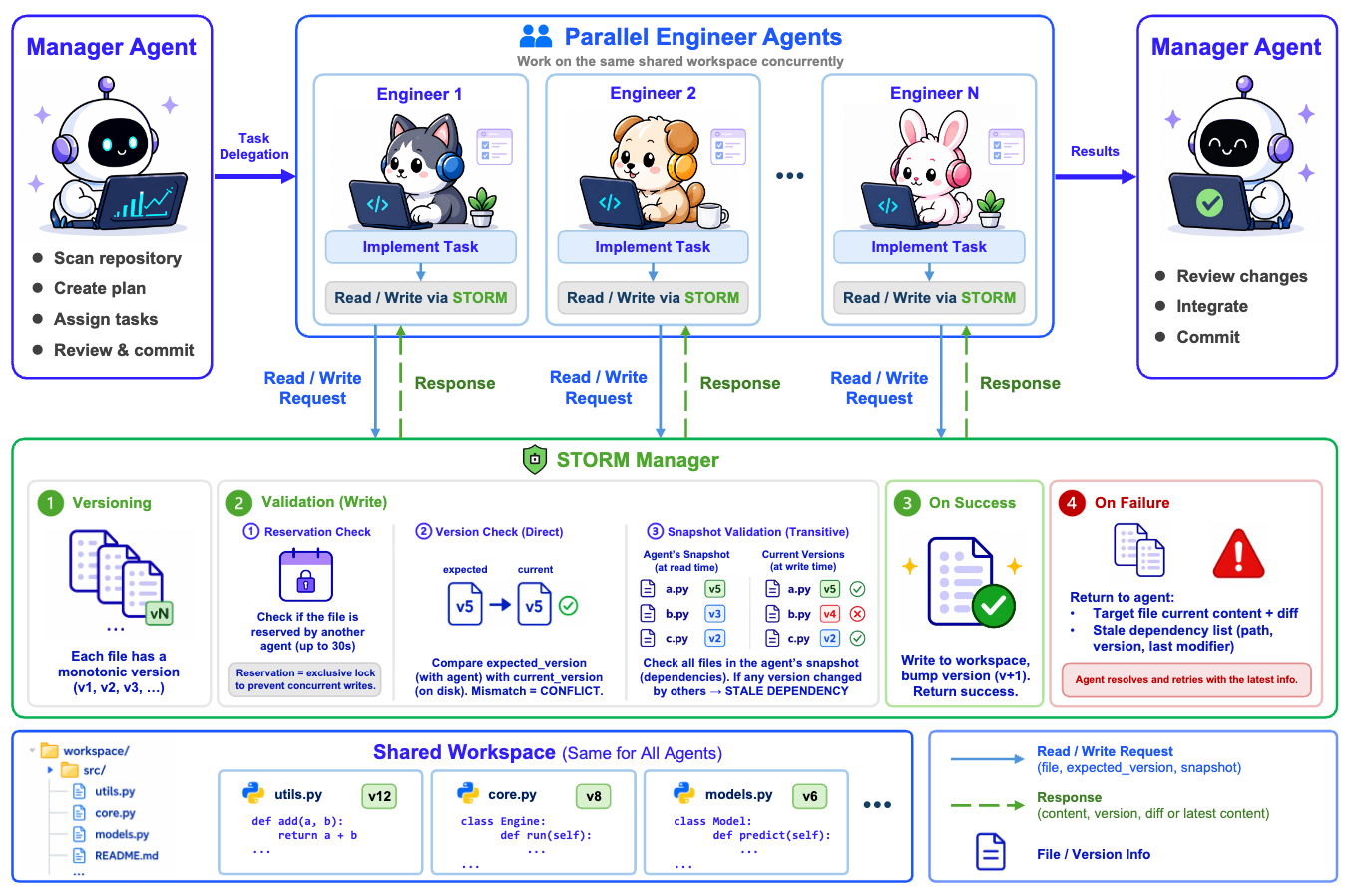
Recent advances in multi-agent systems have shown great potential for solving complex tasks. However, when multiple agents edit a shared codebase concurrently, their changes can silently conflict and inconsistent views lead to integration failures. Existing multi-agent systems address this through workspace isolation (e.g., one git worktree per agent), but this defers conflict resolution to a post-hoc merge step where recovery is expensive. In this paper, we propose STORM, i.e., STate-ORiented Management for multi-agent collaboration. Specifically, STORM manages agent states by mediating their interactions with the shared workspace, ensuring that each agent operates on a consistent view of the codebase and that conflicting edits are detected and resolved at write time.We evaluate STORM on Commit0 and PaperBench across multiple LLMs. STORM outperforms the git-worktree-based multi-agent baseline by +18.7 on Commit0-Lite and +1.4 on PaperBench, while achieving comparable or better cost efficiency. Combined with single-agent runs, STORM reaches highest scores of 87.6 and 78.2 on the two benchmarks respectively, suggesting that explicit state management is a more effective foundation for multi-agent collaboration than workspace isolation. STORM can also be plugged into any multi-agent system.
![]()
![]()
![]()
Multi-agent Collaboration with State Management
Mengyang Liu, Taozhi Chen, Zhenhua Xu, Xue Jiang, Yihong Dong
Under review. May 2026
Recent advances in multi-agent systems have shown great potential for solving complex tasks. However, when multiple agents edit a shared codebase concurrently, their changes can silently conflict and inconsistent views lead to integration failures. Existing multi-agent systems address this through workspace isolation (e.g., one git worktree per agent), but this defers conflict resolution to a post-hoc merge step where recovery is expensive. In this paper, we propose STORM, i.e., STate-ORiented Management for multi-agent collaboration. Specifically, STORM manages agent states by mediating their interactions with the shared workspace, ensuring that each agent operates on a consistent view of the codebase and that conflicting edits are detected and resolved at write time.We evaluate STORM on Commit0 and PaperBench across multiple LLMs. STORM outperforms the git-worktree-based multi-agent baseline by +18.7 on Commit0-Lite and +1.4 on PaperBench, while achieving comparable or better cost efficiency. Combined with single-agent runs, STORM reaches highest scores of 87.6 and 78.2 on the two benchmarks respectively, suggesting that explicit state management is a more effective foundation for multi-agent collaboration than workspace isolation. STORM can also be plugged into any multi-agent system.
![]()
![]()
![]()
MEMCoder: Multi-dimensional Evolving Memory for Private-Library-Oriented Code Generation
Mofei Li*, Taozhi Chen*, Guowei Yang, Jia Li (* equal contribution)
arXiv Apr 2026
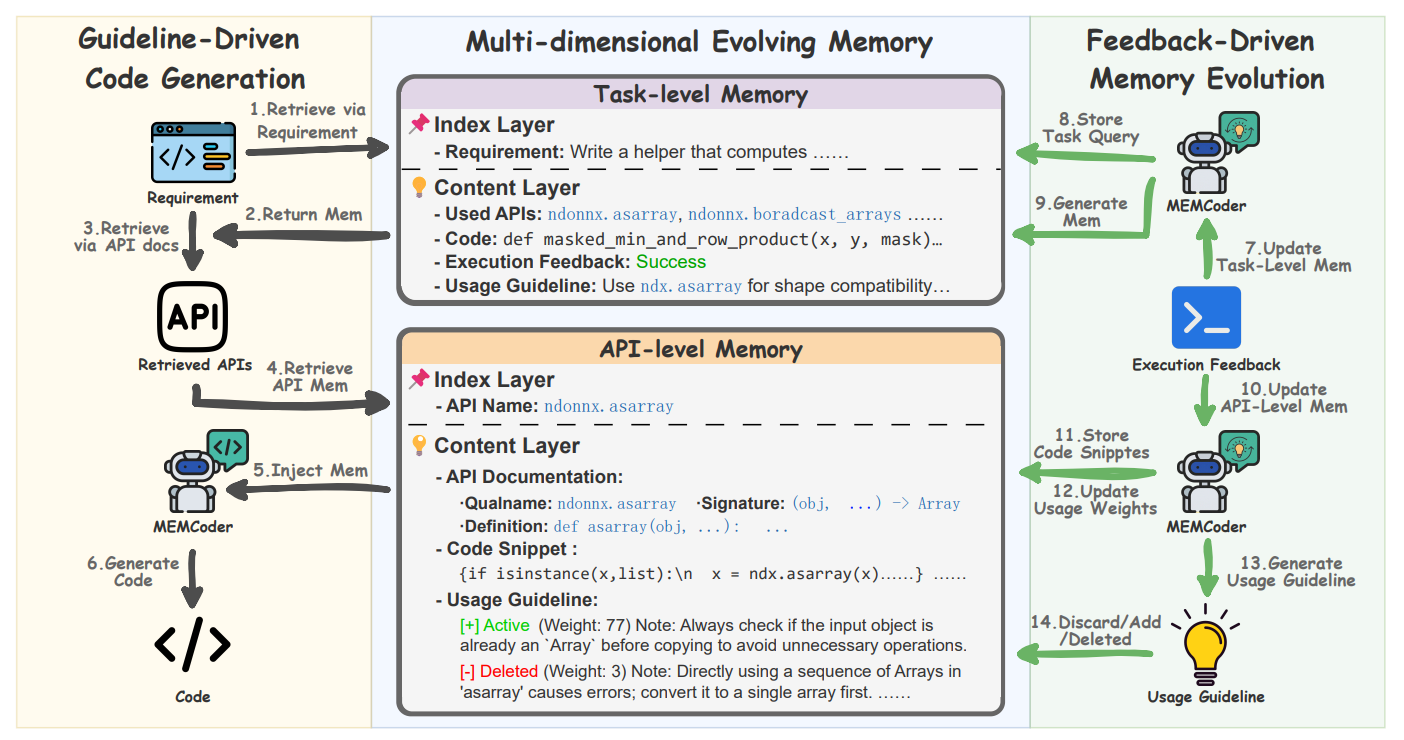
Large Language Models (LLMs) excel at general code generation, but their performance drops sharply in enterprise settings that rely on internal private libraries absent from public pre-training corpora. While Retrieval-Augmented Generation (RAG) offers a training-free alternative by providing static API documentation, we find that such documentation typically provides only isolated definitions, leaving a fundamental knowledge gap. Specifically, LLMs struggle with a task-level lack of coordination patterns between APIs and an API-level misunderstanding of parameter constraints and boundary conditions. To address this, we propose MEMCoder, a novel framework that enables LLMs to autonomously accumulate and evolve Usage Guidelines across these two dimensions. MEMCoder introduces a Multi-dimensional Evolving Memory that captures distilled lessons from the model's own problem-solving trajectories. During inference, MEMCoder employs a dual-source retrieval mechanism to inject both static documentation and relevant historical guidelines into the context. The framework operates in an automated closed loop by using objective execution feedback to reflect on successes and failures, resolve knowledge conflicts, and dynamically update memory. Extensive evaluations on the NdonnxEval and NumbaEval benchmarks demonstrate that MEMCoder substantially enhances existing RAG systems, yielding an average absolute pass@1 gain of 16.31%. Furthermore, MEMCoder exhibits vastly superior domain-specific adaptation compared to existing memory-based continual learning methods.
![]()
MEMCoder: Multi-dimensional Evolving Memory for Private-Library-Oriented Code Generation
Mofei Li*, Taozhi Chen*, Guowei Yang, Jia Li (* equal contribution)
arXiv Apr 2026
Large Language Models (LLMs) excel at general code generation, but their performance drops sharply in enterprise settings that rely on internal private libraries absent from public pre-training corpora. While Retrieval-Augmented Generation (RAG) offers a training-free alternative by providing static API documentation, we find that such documentation typically provides only isolated definitions, leaving a fundamental knowledge gap. Specifically, LLMs struggle with a task-level lack of coordination patterns between APIs and an API-level misunderstanding of parameter constraints and boundary conditions. To address this, we propose MEMCoder, a novel framework that enables LLMs to autonomously accumulate and evolve Usage Guidelines across these two dimensions. MEMCoder introduces a Multi-dimensional Evolving Memory that captures distilled lessons from the model's own problem-solving trajectories. During inference, MEMCoder employs a dual-source retrieval mechanism to inject both static documentation and relevant historical guidelines into the context. The framework operates in an automated closed loop by using objective execution feedback to reflect on successes and failures, resolve knowledge conflicts, and dynamically update memory. Extensive evaluations on the NdonnxEval and NumbaEval benchmarks demonstrate that MEMCoder substantially enhances existing RAG systems, yielding an average absolute pass@1 gain of 16.31%. Furthermore, MEMCoder exhibits vastly superior domain-specific adaptation compared to existing memory-based continual learning methods.
![]()
Think Anywhere in Code Generation
Xue Jiang, Tianyu Zhang, Mengyang Liu, Taozhi Chen, Zhenhua Xu, Wenpin Jiao, Zhi Jin, Ge Li, Yihong Dong
arXiv Mar 2026
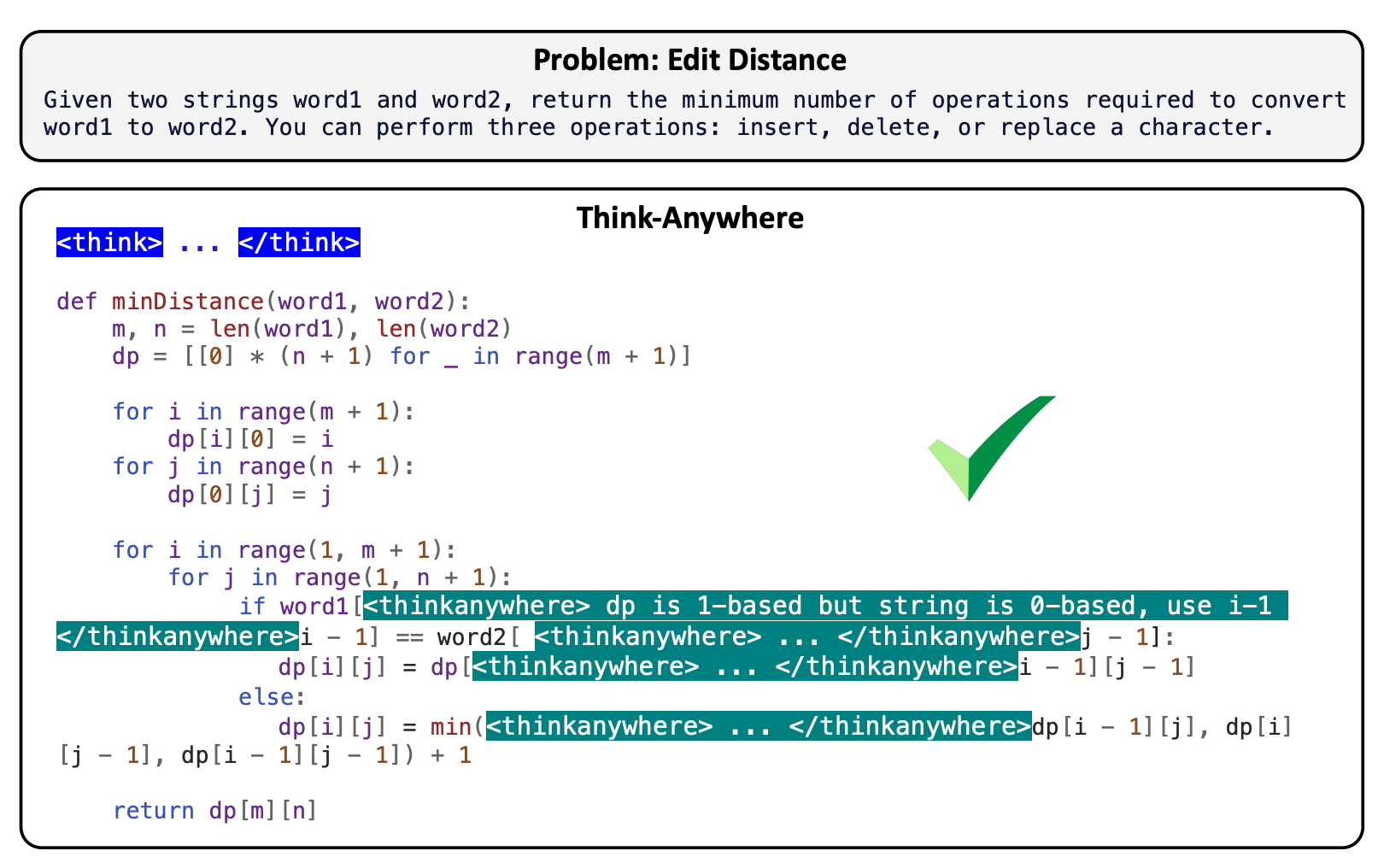
Recent advances in reasoning Large Language Models (LLMs) have primarily relied on upfront thinking, where reasoning occurs before final answer. However, this approach suffers from critical limitations in code generation, where upfront thinking is often insufficient as problems' full complexity only reveals itself during code implementation. Moreover, it cannot adaptively allocate reasoning effort throughout the code generation process where difficulty varies significantly. In this paper, we propose Think-Anywhere, a novel reasoning mechanism that enables LLMs to invoke thinking on-demand at any token position during code generation. We achieve Think-Anywhere by first teaching LLMs to imitate the reasoning patterns through cold-start training, then leveraging outcome-based RL rewards to drive the model's autonomous exploration of when and where to invoke reasoning. Extensive experiments on four mainstream code generation benchmarks (i.e., LeetCode, LiveCodeBench, HumanEval, and MBPP) show that Think-Anywhere achieves state-of-the-art performance over both existing reasoning methods and recent post-training approaches, while demonstrating consistent generalization across diverse LLMs. Our analysis further reveals that Think-Anywhere enables the model to adaptively invoke reasoning at high-entropy positions, providing enhanced interpretability.
![]()
![]()
![]()
![]()
Think Anywhere in Code Generation
Xue Jiang, Tianyu Zhang, Mengyang Liu, Taozhi Chen, Zhenhua Xu, Wenpin Jiao, Zhi Jin, Ge Li, Yihong Dong
arXiv Mar 2026
Recent advances in reasoning Large Language Models (LLMs) have primarily relied on upfront thinking, where reasoning occurs before final answer. However, this approach suffers from critical limitations in code generation, where upfront thinking is often insufficient as problems' full complexity only reveals itself during code implementation. Moreover, it cannot adaptively allocate reasoning effort throughout the code generation process where difficulty varies significantly. In this paper, we propose Think-Anywhere, a novel reasoning mechanism that enables LLMs to invoke thinking on-demand at any token position during code generation. We achieve Think-Anywhere by first teaching LLMs to imitate the reasoning patterns through cold-start training, then leveraging outcome-based RL rewards to drive the model's autonomous exploration of when and where to invoke reasoning. Extensive experiments on four mainstream code generation benchmarks (i.e., LeetCode, LiveCodeBench, HumanEval, and MBPP) show that Think-Anywhere achieves state-of-the-art performance over both existing reasoning methods and recent post-training approaches, while demonstrating consistent generalization across diverse LLMs. Our analysis further reveals that Think-Anywhere enables the model to adaptively invoke reasoning at high-entropy positions, providing enhanced interpretability.
![]()
![]()
![]()
![]()
What Papers Don't Tell You: Recovering Tacit Knowledge for Automated Paper Reproduction
Lehui Li, Ruining Wang, Haochen Song, Yaoxin Mao, Tong Zhang, Yuyao Wang, Jiayi Fan, Yitong Zhang, Taozhi Chen, Jieping Ye, Chengqi Zhang, Yongshun Gong
arXiv Mar 2026
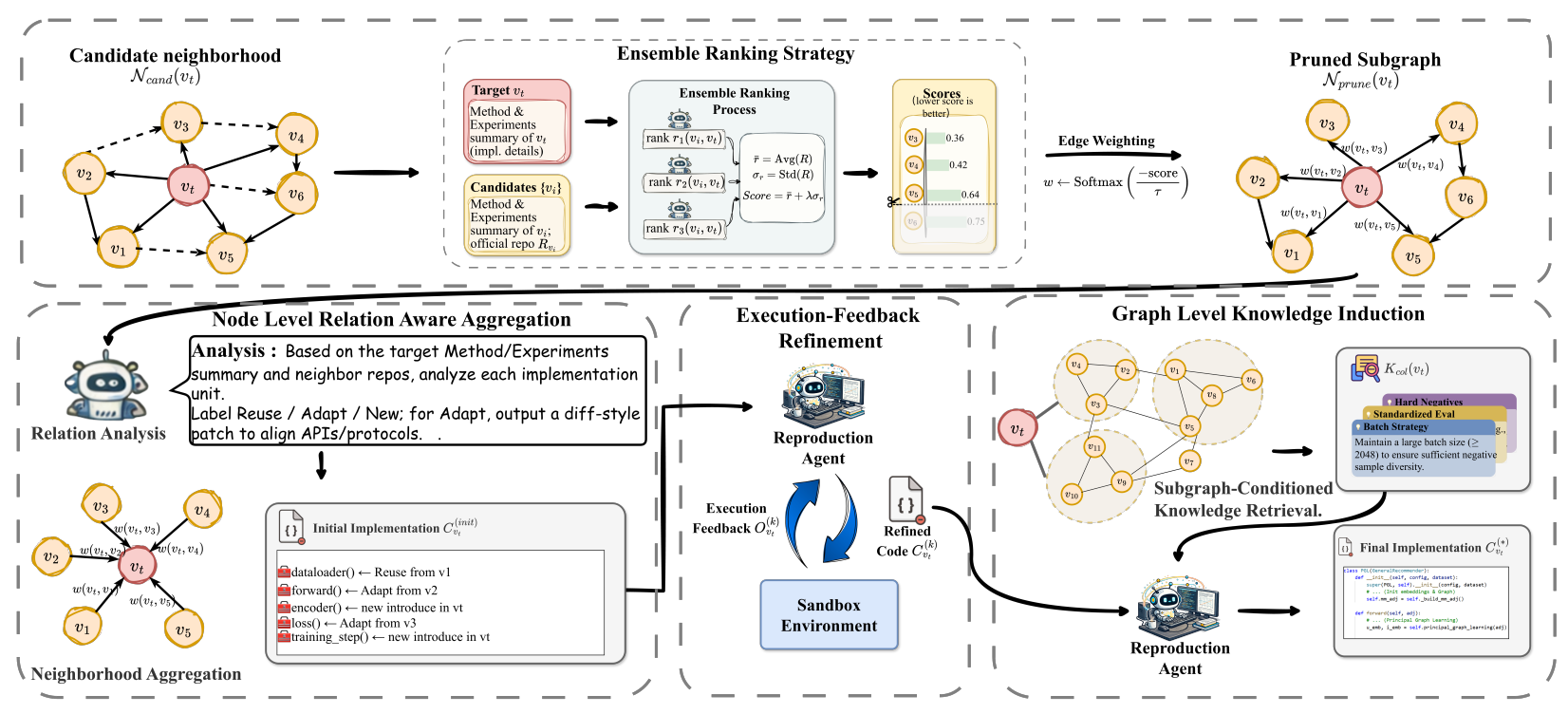
Automated paper reproduction seeks to generate executable code implementations from academic papers, substantially reducing the cost of research validation and reuse while accelerating the accumulation of scientific knowledge. Existing approaches retrieve and concatenate text and code snippets from citation neighborhoods, yet fail to capture the knowledge implicitly encoded in the relational structure among papers. We argue that the knowledge essential for reproduction naturally resides at two distinct levels of the paper graph: (i) globally shared common knowledge within a domain, and (ii) undocumented local aggregation details between the target paper and its predecessor works. To address this, we propose PaperRep, a multi-scale graph reasoning framework that first applies semantic graph pruning to select implementation-relevant nodes from the paper graph, then employs a global graph reasoning module to distill stable reproduction patterns within the domain and a local graph reasoning module to characterize implementation aggregation relationships between the target paper and its neighbors. Extensive experiments on an extended ReproduceBench covering 10 tasks and 40 recent papers show that PaperRep achieves an average performance gap of 10.04% against official implementations, improving over the strongest baseline by 24.68%, thereby validating the necessity and effectiveness of explicit graph-structured reasoning for automated paper reproduction.
![]()
![]()
What Papers Don't Tell You: Recovering Tacit Knowledge for Automated Paper Reproduction
Lehui Li, Ruining Wang, Haochen Song, Yaoxin Mao, Tong Zhang, Yuyao Wang, Jiayi Fan, Yitong Zhang, Taozhi Chen, Jieping Ye, Chengqi Zhang, Yongshun Gong
arXiv Mar 2026
Automated paper reproduction seeks to generate executable code implementations from academic papers, substantially reducing the cost of research validation and reuse while accelerating the accumulation of scientific knowledge. Existing approaches retrieve and concatenate text and code snippets from citation neighborhoods, yet fail to capture the knowledge implicitly encoded in the relational structure among papers. We argue that the knowledge essential for reproduction naturally resides at two distinct levels of the paper graph: (i) globally shared common knowledge within a domain, and (ii) undocumented local aggregation details between the target paper and its predecessor works. To address this, we propose PaperRep, a multi-scale graph reasoning framework that first applies semantic graph pruning to select implementation-relevant nodes from the paper graph, then employs a global graph reasoning module to distill stable reproduction patterns within the domain and a local graph reasoning module to characterize implementation aggregation relationships between the target paper and its neighbors. Extensive experiments on an extended ReproduceBench covering 10 tasks and 40 recent papers show that PaperRep achieves an average performance gap of 10.04% against official implementations, improving over the strongest baseline by 24.68%, thereby validating the necessity and effectiveness of explicit graph-structured reasoning for automated paper reproduction.
![]()
![]()
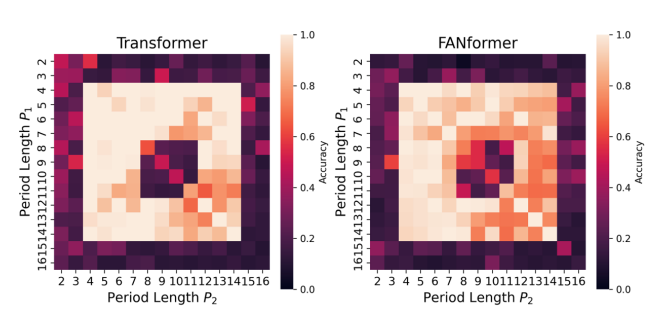
Do Transformers Have the Ability for Periodicity Generalization?
Huanyu Liu, Ge Li, Yihong Dong, Sihan Wu, Peixu Wang, Sihao Cheng, Taozhi Chen, Kechi Zhang, Hao Zhu, Tongxuan Liu
arXiv Jan 2026
Large language models (LLMs) based on the Transformer have demonstrated strong performance across diverse tasks. However, current models still exhibit limitations in out-of-distribution (OOD) generalization compared with humans. We investigate this gap through periodicity, one of the basic OOD scenarios. Periodicity captures invariance amid variation. Periodicity generalization represents a model's ability to extract periodic patterns from training data and generalize to OOD scenarios. We introduce a unified interpretation of periodicity from the perspective of abstract algebra and reasoning, including both single and composite periodicity, to analyze why Transformers struggle to generalize periodicity. Then we construct Coper about composite periodicity, a controllable generative dataset with two OOD settings, Hollow and Extrapolation. Experiments reveal that periodicity generalization in Transformers is limited, where models can memorize periodic data during training, but cannot generalize to unseen composite periodicity. We release the source code to support future research.
![]()
![]()
Do Transformers Have the Ability for Periodicity Generalization?
Huanyu Liu, Ge Li, Yihong Dong, Sihan Wu, Peixu Wang, Sihao Cheng, Taozhi Chen, Kechi Zhang, Hao Zhu, Tongxuan Liu
arXiv Jan 2026
Large language models (LLMs) based on the Transformer have demonstrated strong performance across diverse tasks. However, current models still exhibit limitations in out-of-distribution (OOD) generalization compared with humans. We investigate this gap through periodicity, one of the basic OOD scenarios. Periodicity captures invariance amid variation. Periodicity generalization represents a model's ability to extract periodic patterns from training data and generalize to OOD scenarios. We introduce a unified interpretation of periodicity from the perspective of abstract algebra and reasoning, including both single and composite periodicity, to analyze why Transformers struggle to generalize periodicity. Then we construct Coper about composite periodicity, a controllable generative dataset with two OOD settings, Hollow and Extrapolation. Experiments reveal that periodicity generalization in Transformers is limited, where models can memorize periodic data during training, but cannot generalize to unseen composite periodicity. We release the source code to support future research.
![]()
![]()
2025
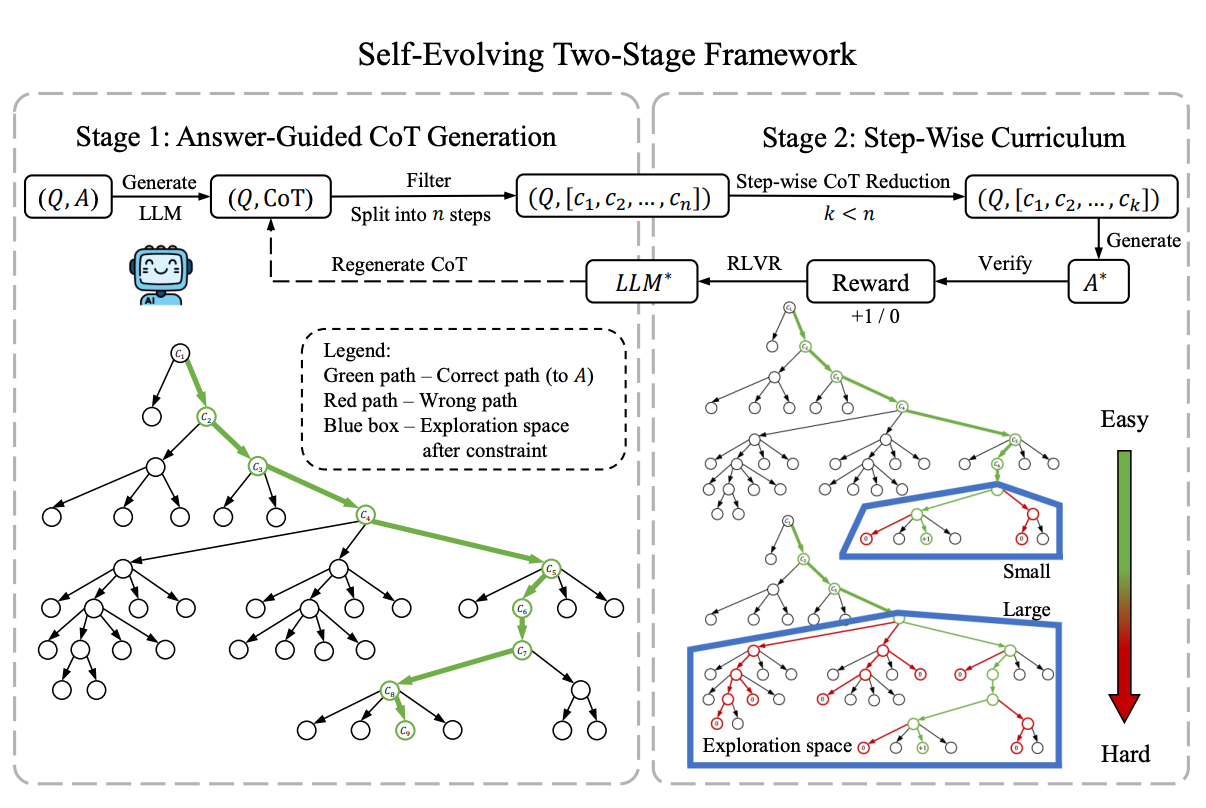
EvoCoT: Overcoming the Exploration Bottleneck in Reinforcement Learning
Huanyu Liu, Jia Li, Chang Yu, Taozhi Chen, Yihong Dong, Lecheng Wang, XiaoLong Hu, Ge Li
The 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026 Findings) Aug 2025
Reinforcement learning with verifiable reward (RLVR) has become a promising paradigm for post-training large language models (LLMs) to improve their reasoning capability. However, when the rollout accuracy is low on hard problems, the reward becomes sparse, limiting learning efficiency and causing exploration bottlenecks. Existing approaches either rely on teacher models for distillation or filter out difficult problems, which limits scalability or restricts reasoning improvement through exploration.
We propose EvoCoT, a self-evolving curriculum learning framework based on two-stage chain-of-thought (CoT) reasoning optimization. EvoCoT constrains the exploration space by self-generating and verifying CoT trajectories, then gradually shortens CoT steps to expand the space in a controlled way. The framework enables LLMs to stably learn from initially unsolved hard problems under sparse rewards. We apply EvoCoT to multiple LLM families, including Qwen, DeepSeek, and Llama. Experiments show that EvoCoT enables LLMs to solve previously unsolved problems, improves reasoning capability without external CoT supervision, and is compatible with various RL fine-tuning methods. We release the source code to support future research.
![]()
![]()
EvoCoT: Overcoming the Exploration Bottleneck in Reinforcement Learning
Huanyu Liu, Jia Li, Chang Yu, Taozhi Chen, Yihong Dong, Lecheng Wang, XiaoLong Hu, Ge Li
The 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026 Findings) Aug 2025
Reinforcement learning with verifiable reward (RLVR) has become a promising paradigm for post-training large language models (LLMs) to improve their reasoning capability. However, when the rollout accuracy is low on hard problems, the reward becomes sparse, limiting learning efficiency and causing exploration bottlenecks. Existing approaches either rely on teacher models for distillation or filter out difficult problems, which limits scalability or restricts reasoning improvement through exploration.
We propose EvoCoT, a self-evolving curriculum learning framework based on two-stage chain-of-thought (CoT) reasoning optimization. EvoCoT constrains the exploration space by self-generating and verifying CoT trajectories, then gradually shortens CoT steps to expand the space in a controlled way. The framework enables LLMs to stably learn from initially unsolved hard problems under sparse rewards. We apply EvoCoT to multiple LLM families, including Qwen, DeepSeek, and Llama. Experiments show that EvoCoT enables LLMs to solve previously unsolved problems, improves reasoning capability without external CoT supervision, and is compatible with various RL fine-tuning methods. We release the source code to support future research.
![]()
![]()