

I am a PhD student in Computer Science at Emory University, where I am advised by Prof. Joon-Seok Kim in the AI and Simulation Lab. Before joining Emory, I worked as a Research Assistant at the College of AI, Tsinghua University, and also conducted research at Peking University under Prof. Ge Li and at Microsoft under Prof. Lee Stott. I graduated from Imperial College London and Tsinghua University.
My research interests include AI agents, large language models, multi-agent systems, and data science. I am particularly interested in building intelligent systems that can reason, interact with tools and environments, and operate robustly in complex real-world settings. More broadly, I aim to bridge research and engineering to make AI systems not only more capable, but also more dependable and practically useful.
I welcome conversations and collaborations with researchers and engineers interested in AI agents, applied machine learning, and intelligent systems.
Education
-
 Emory UniversitySep. 2026 - Present
Emory UniversitySep. 2026 - Present -
 Imperial College LondonMSc in Data Science and Machine Learning
Imperial College LondonMSc in Data Science and Machine Learning
Supervisor: Prof. Gerard Gorman
Lab Director: Prof. Rossella Arcucci
Ada Lovelace AcademySep. 2024 - Sep. 2025
Experience
-
 Tsinghua UniversitySep. 2025 - Aug. 2026
Tsinghua UniversitySep. 2025 - Aug. 2026 -
 MicrosoftApr. 2025 - Sep. 2025
MicrosoftApr. 2025 - Sep. 2025 -
 Peking UniversityJun. 2024 - Nov. 2025
Peking UniversityJun. 2024 - Nov. 2025 -
 Tsinghua UniversityJun. 2023 - Jun. 2024
Tsinghua UniversityJun. 2023 - Jun. 2024
Honors & Awards (view all )
-
Laney Graduate School Fellowship,
Emory University2026 -
China-U.S. Young Maker Competition,
National First Prize (Main Track)2024
News
Selected Publications (view all )
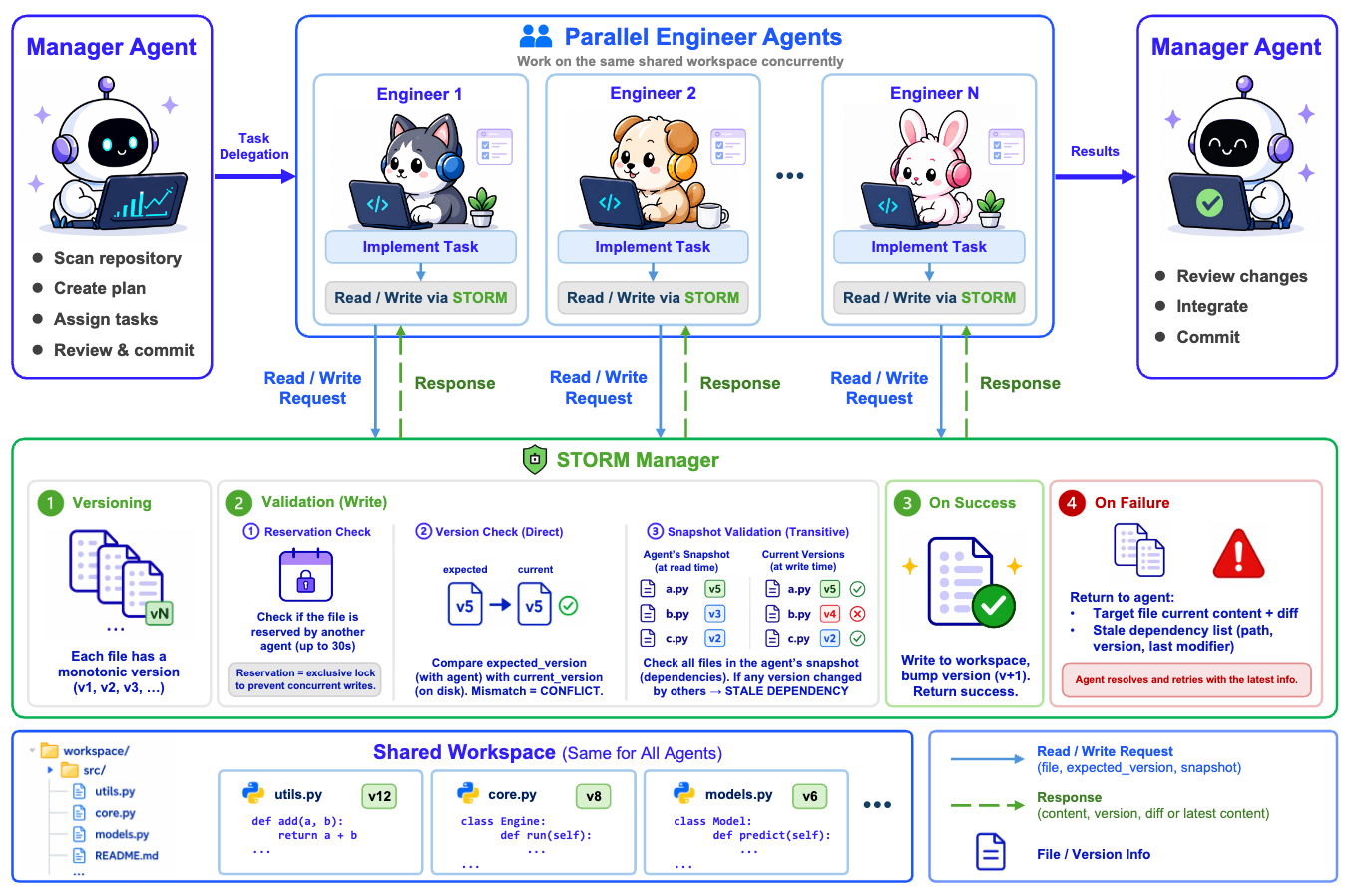
Multi-agent Collaboration with State Management
Mengyang Liu, Taozhi Chen, Zhenhua Xu, Xue Jiang, Yihong Dong
Under review. May 2026
Recent advances in multi-agent systems have shown great potential for solving complex tasks. However, when multiple agents edit a shared codebase concurrently, their changes can silently conflict and inconsistent views lead to integration failures. Existing multi-agent systems address this through workspace isolation (e.g., one git worktree per agent), but this defers conflict resolution to a post-hoc merge step where recovery is expensive. In this paper, we propose STORM, i.e., STate-ORiented Management for multi-agent collaboration. Specifically, STORM manages agent states by mediating their interactions with the shared workspace, ensuring that each agent operates on a consistent view of the codebase and that conflicting edits are detected and resolved at write time.We evaluate STORM on Commit0 and PaperBench across multiple LLMs. STORM outperforms the git-worktree-based multi-agent baseline by +18.7 on Commit0-Lite and +1.4 on PaperBench, while achieving comparable or better cost efficiency. Combined with single-agent runs, STORM reaches highest scores of 87.6 and 78.2 on the two benchmarks respectively, suggesting that explicit state management is a more effective foundation for multi-agent collaboration than workspace isolation. STORM can also be plugged into any multi-agent system.
![]()
![]()
![]()
Multi-agent Collaboration with State Management
Mengyang Liu, Taozhi Chen, Zhenhua Xu, Xue Jiang, Yihong Dong
Under review. May 2026
Recent advances in multi-agent systems have shown great potential for solving complex tasks. However, when multiple agents edit a shared codebase concurrently, their changes can silently conflict and inconsistent views lead to integration failures. Existing multi-agent systems address this through workspace isolation (e.g., one git worktree per agent), but this defers conflict resolution to a post-hoc merge step where recovery is expensive. In this paper, we propose STORM, i.e., STate-ORiented Management for multi-agent collaboration. Specifically, STORM manages agent states by mediating their interactions with the shared workspace, ensuring that each agent operates on a consistent view of the codebase and that conflicting edits are detected and resolved at write time.We evaluate STORM on Commit0 and PaperBench across multiple LLMs. STORM outperforms the git-worktree-based multi-agent baseline by +18.7 on Commit0-Lite and +1.4 on PaperBench, while achieving comparable or better cost efficiency. Combined with single-agent runs, STORM reaches highest scores of 87.6 and 78.2 on the two benchmarks respectively, suggesting that explicit state management is a more effective foundation for multi-agent collaboration than workspace isolation. STORM can also be plugged into any multi-agent system.
![]()
![]()
![]()
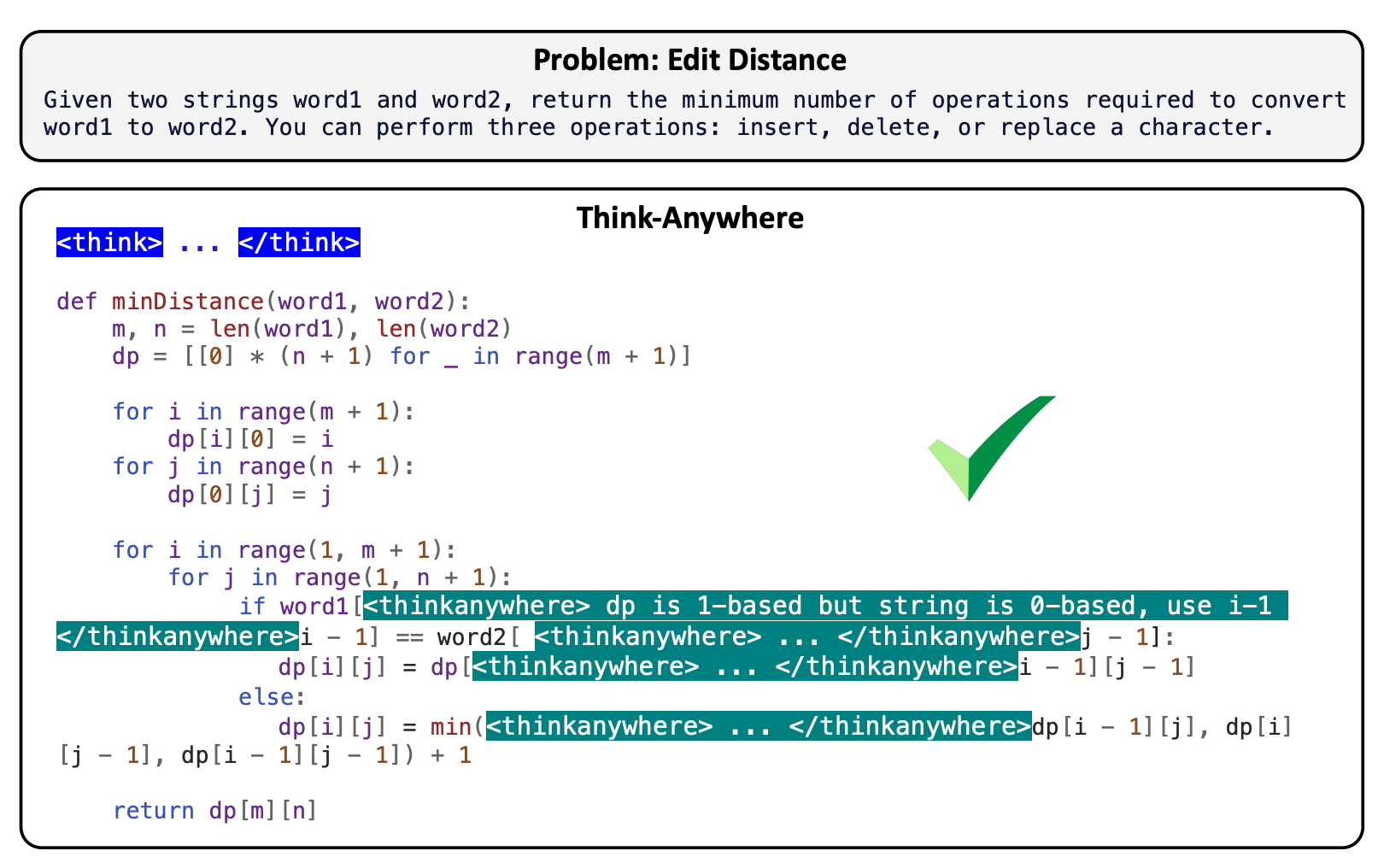
Think Anywhere in Code Generation
Xue Jiang, Tianyu Zhang, Mengyang Liu, Taozhi Chen, Zhenhua Xu, Wenpin Jiao, Zhi Jin, Ge Li, Yihong Dong
arXiv Mar 2026
Recent advances in reasoning Large Language Models (LLMs) have primarily relied on upfront thinking, where reasoning occurs before final answer. However, this approach suffers from critical limitations in code generation, where upfront thinking is often insufficient as problems' full complexity only reveals itself during code implementation. Moreover, it cannot adaptively allocate reasoning effort throughout the code generation process where difficulty varies significantly. In this paper, we propose Think-Anywhere, a novel reasoning mechanism that enables LLMs to invoke thinking on-demand at any token position during code generation. We achieve Think-Anywhere by first teaching LLMs to imitate the reasoning patterns through cold-start training, then leveraging outcome-based RL rewards to drive the model's autonomous exploration of when and where to invoke reasoning. Extensive experiments on four mainstream code generation benchmarks (i.e., LeetCode, LiveCodeBench, HumanEval, and MBPP) show that Think-Anywhere achieves state-of-the-art performance over both existing reasoning methods and recent post-training approaches, while demonstrating consistent generalization across diverse LLMs. Our analysis further reveals that Think-Anywhere enables the model to adaptively invoke reasoning at high-entropy positions, providing enhanced interpretability.
![]()
![]()
![]()
![]()
Think Anywhere in Code Generation
Xue Jiang, Tianyu Zhang, Mengyang Liu, Taozhi Chen, Zhenhua Xu, Wenpin Jiao, Zhi Jin, Ge Li, Yihong Dong
arXiv Mar 2026
Recent advances in reasoning Large Language Models (LLMs) have primarily relied on upfront thinking, where reasoning occurs before final answer. However, this approach suffers from critical limitations in code generation, where upfront thinking is often insufficient as problems' full complexity only reveals itself during code implementation. Moreover, it cannot adaptively allocate reasoning effort throughout the code generation process where difficulty varies significantly. In this paper, we propose Think-Anywhere, a novel reasoning mechanism that enables LLMs to invoke thinking on-demand at any token position during code generation. We achieve Think-Anywhere by first teaching LLMs to imitate the reasoning patterns through cold-start training, then leveraging outcome-based RL rewards to drive the model's autonomous exploration of when and where to invoke reasoning. Extensive experiments on four mainstream code generation benchmarks (i.e., LeetCode, LiveCodeBench, HumanEval, and MBPP) show that Think-Anywhere achieves state-of-the-art performance over both existing reasoning methods and recent post-training approaches, while demonstrating consistent generalization across diverse LLMs. Our analysis further reveals that Think-Anywhere enables the model to adaptively invoke reasoning at high-entropy positions, providing enhanced interpretability.
![]()
![]()
![]()
![]()